mono
Septembre 4, 2024, 8:30
1
HEllo la team ,
J’ai une question pour vous.
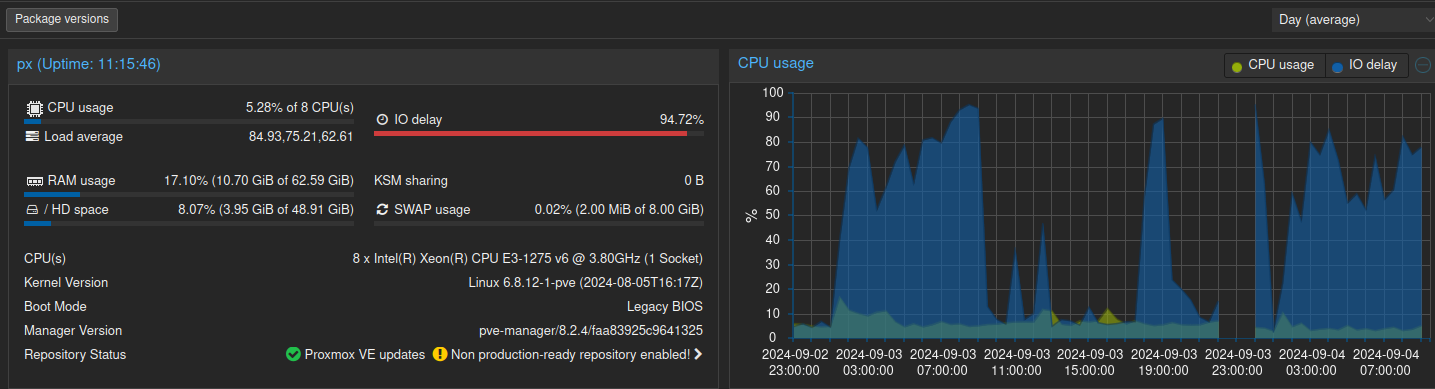
Depuis qques jours , j’ai des IoDelay de malade et mes saves sont de très très longues .
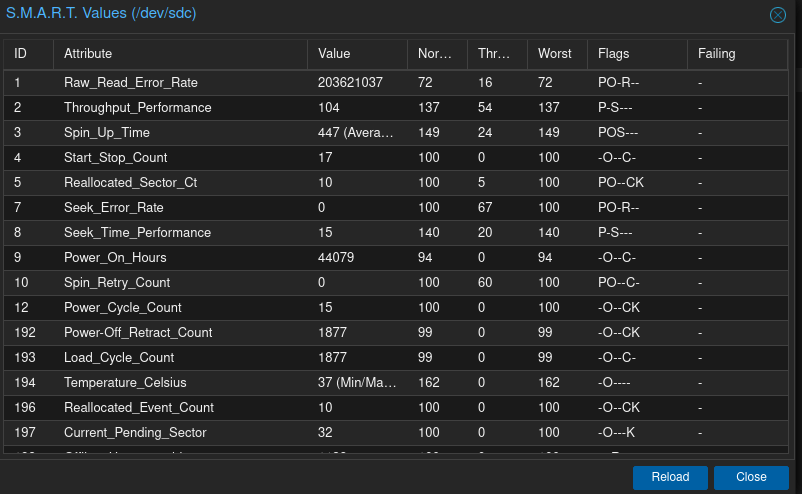
En essayant de comprendre le pourquoi du comment, j’ai check les SMART values d’un des disques : 6 TB SATA Enterprise Hard Drive
J’ai toujours du mal à capter les valeurs S.M.A.R.T … mais cela me parait un peu inquiétant .
Qu’en pensez vous ?
This is bad.
Surveille la valeur « Reallocated Event Count », elle ne doit pas monter.
mono
Septembre 4, 2024, 9:08
3
nope je n’ai que ça
( j’ai aussi une ticket coté Proxmox IODelay very high since few days | Proxmox Support Forum )
damaki
Septembre 4, 2024, 9:31
4
io delay, ça veut dire tout et n’importe quoi. Ça veut juste dire que t’as une très grosse activité sur les disques, à tel point que certaines tâches doivent attendre.
À noter que de base, Proxmox ça bouffe pas mal d’io pour la télémétrie du serveur et des VMs, mais pas suffisamment pour que ça impacte les perfs en général.
Mais ca peut aussi être un disque qui crève
@mono T’as remarqué une augmentation de l’activité sur ton serveur récemment?
Sinon la valeur offline_uncorrectable est assez haute, sous linux il suffit d’aller dans dmesg pour avoir les dernières erreurs d’I/O, dans proxmox je sais pas
mono
Septembre 4, 2024, 9:53
6
c’est monter sur un debian 12 , donc oui j’ai une dmesg .
[Wed Sep 4 03:41:05 2024] loop26: detected capacity change from 0 to 16777216
[Wed Sep 4 03:42:02 2024] EXT4-fs (loop26): 5 orphan inodes deleted
errr loop26?
Dans ce cas la, il me semble qu’il faut regarder le log LVM, tu n’auras rien dans dmesg
mono
Septembre 12, 2024, 6:53
10
Ok je reviens vers vous .
La situation est redevenue normale, mais cela n’explique pas mon problème de tar /rsync très très long sur mon disque / PV / VG .
Comment puis je savoir ce qui pose problème ?
mono
Septembre 13, 2024, 6:28
11
démontage du disque / smartctl :
root # smartctl -l selftest /dev/sdd
smartctl 7.3 2022-02-28 r5338 [x86_64-linux-6.8.12-1-pve] (local build)
Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 35163 -
# 2 Short offline Completed without error 00% 35146 -
# 3 Extended offline Completed without error 00% 35144 -
# 4 Extended offline Completed: read failure 90% 35100 8071176
# 5 Extended offline Completed without error 00% 35065 -
# 6 Extended offline Completed without error 00% 35039 -
# 7 Extended offline Completed without error 00% 35012 -
# 8 Extended offline Completed without error 00% 34987 -
# 9 Extended offline Completed without error 00% 25264 -
#10 Extended offline Completed without error 00% 25238 -
#11 Extended offline Completed without error 00% 25064 -
#12 Extended offline Completed without error 00% 25038 -
#13 Extended offline Completed without error 00% 8729 -
#14 Extended offline Completed without error 00% 8703 -
1 of 1 failed self-tests are outdated by newer successful extended offline self-test # 1
dois-je m’inquiéter ? ou aucun soucis mec ?
Affiche plutôt les valeurs smart, ce que tu montres ici est la liste des autotests mais on ne sait pas a quoi ca correspond.
mono
Septembre 13, 2024, 1:06
13
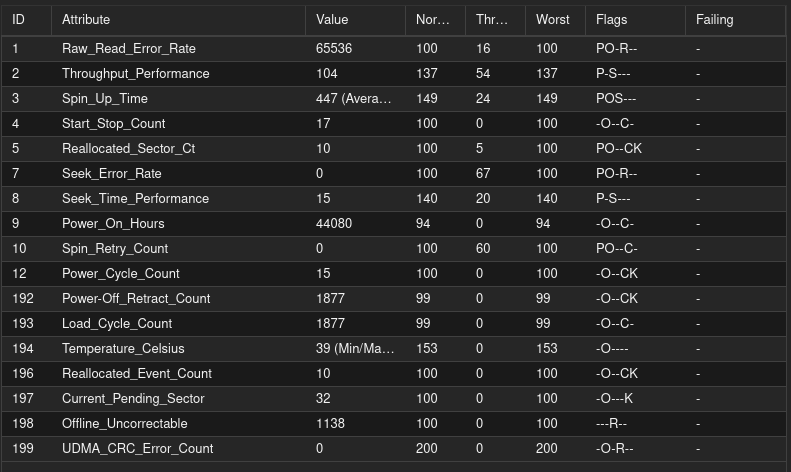
voila le tout
smartctl --all /dev/sdd
smartctl 7.3 2022-02-28 r5338 [x86_64-linux-6.8.12-1-pve] (local build)
Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: HGST Ultrastar 7K6000
Device Model: HGST HUS726060ALE610
Serial Number: K1G0A84B
LU WWN Device Id: 5 000cca 255c02686
Firmware Version: APGNTD05
User Capacity: 6,001,175,126,016 bytes [6.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database 7.3/5319
ATA Version is: ACS-2, ATA8-ACS T13/1699-D revision 4
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Fri Sep 13 15:04:49 2024 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 241) Self-test routine in progress...
10% of test remaining.
Total time to complete Offline
data collection: ( 113) seconds.
Offline data collection
capabilities: (0x5b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 746) minutes.
SCT capabilities: (0x003d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 016 Pre-fail Always - 0
2 Throughput_Performance 0x0005 137 137 054 Pre-fail Offline - 104
3 Spin_Up_Time 0x0007 149 149 024 Pre-fail Always - 447 (Average 437)
4 Start_Stop_Count 0x0012 100 100 000 Old_age Always - 18
5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 10
7 Seek_Error_Rate 0x000b 100 100 067 Pre-fail Always - 0
8 Seek_Time_Performance 0x0005 140 140 020 Pre-fail Offline - 15
9 Power_On_Hours 0x0012 094 094 000 Old_age Always - 44300
10 Spin_Retry_Count 0x0013 100 100 060 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 16
192 Power-Off_Retract_Count 0x0032 099 099 000 Old_age Always - 1884
193 Load_Cycle_Count 0x0012 099 099 000 Old_age Always - 1884
194 Temperature_Celsius 0x0002 153 153 000 Old_age Always - 39 (Min/Max 25/56)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 10
197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 32
198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline - 1138
199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 0
SMART Error Log Version: 1
ATA Error Count: 254 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 254 occurred at disk power-on lifetime: 44063 hours (1835 days + 23 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 43 00 00 00 00 00 Error: UNC at LBA = 0x00000000 = 0
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 f8 e0 e8 d9 85 40 08 22d+15:00:04.542 READ FPDMA QUEUED
60 08 e8 e0 9a a7 40 08 22d+15:00:01.430 READ FPDMA QUEUED
61 08 d8 18 65 31 40 08 22d+15:00:01.429 WRITE FPDMA QUEUED
61 08 d0 20 08 fc 40 08 22d+15:00:01.429 WRITE FPDMA QUEUED
61 08 60 e0 2e 11 40 08 22d+15:00:01.429 WRITE FPDMA QUEUED
Error 253 occurred at disk power-on lifetime: 43568 hours (1815 days + 8 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 43 00 00 00 00 00 Error: UNC at LBA = 0x00000000 = 0
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 08 20 88 15 d6 40 08 1d+23:33:08.904 READ FPDMA QUEUED
61 10 a8 c8 ba 01 40 08 1d+23:33:06.074 WRITE FPDMA QUEUED
61 38 a0 58 23 0f 40 08 1d+23:33:06.074 WRITE FPDMA QUEUED
61 08 98 20 a9 07 40 08 1d+23:33:06.074 WRITE FPDMA QUEUED
61 08 90 00 88 e1 40 08 1d+23:33:06.074 WRITE FPDMA QUEUED
Error 252 occurred at disk power-on lifetime: 43568 hours (1815 days + 8 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 43 00 00 00 00 00 Error: UNC at LBA = 0x00000000 = 0
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 08 b0 88 15 d6 40 08 1d+23:33:05.662 READ FPDMA QUEUED
61 08 f8 50 23 0f 40 08 1d+23:33:02.826 WRITE FPDMA QUEUED
61 10 98 20 df 10 40 08 1d+23:33:02.826 WRITE FPDMA QUEUED
61 48 b8 68 7c c1 40 08 1d+23:33:02.826 WRITE FPDMA QUEUED
61 08 a8 68 1c 69 40 08 1d+23:33:02.826 WRITE FPDMA QUEUED
Error 251 occurred at disk power-on lifetime: 43568 hours (1815 days + 8 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 43 00 00 00 00 00 Error: UNC at LBA = 0x00000000 = 0
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 08 40 88 15 d6 40 08 1d+23:33:02.612 READ FPDMA QUEUED
61 38 90 18 23 0f 40 08 1d+23:32:59.986 WRITE FPDMA QUEUED
61 28 30 f0 62 24 40 08 1d+23:32:59.985 WRITE FPDMA QUEUED
61 08 28 00 08 27 40 08 1d+23:32:59.985 WRITE FPDMA QUEUED
61 10 20 a0 41 be 40 08 1d+23:32:59.985 WRITE FPDMA QUEUED
Error 250 occurred at disk power-on lifetime: 43544 hours (1814 days + 8 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 43 00 00 00 00 00 Error: UNC at LBA = 0x00000000 = 0
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 08 40 88 15 d6 40 08 1d+00:07:44.526 READ FPDMA QUEUED
61 08 b8 48 ca 7b 40 08 1d+00:07:41.700 WRITE FPDMA QUEUED
61 08 b0 38 c8 7b 40 08 1d+00:07:41.700 WRITE FPDMA QUEUED
61 08 a8 70 c9 60 40 08 1d+00:07:41.700 WRITE FPDMA QUEUED
61 08 98 58 c9 60 40 08 1d+00:07:41.700 WRITE FPDMA QUEUED
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Aborted by host 90% 44294 -
# 2 Short offline Completed without error 00% 44293 -
# 3 Extended offline Completed without error 00% 35163 -
# 4 Short offline Completed without error 00% 35146 -
# 5 Extended offline Completed without error 00% 35144 -
# 6 Extended offline Completed: read failure 90% 35100 8071176
# 7 Extended offline Completed without error 00% 35065 -
# 8 Extended offline Completed without error 00% 35039 -
# 9 Extended offline Completed without error 00% 35012 -
#10 Extended offline Completed without error 00% 34987 -
#11 Extended offline Completed without error 00% 25264 -
#12 Extended offline Completed without error 00% 25238 -
#13 Extended offline Completed without error 00% 25064 -
#14 Extended offline Completed without error 00% 25038 -
#15 Extended offline Completed without error 00% 8729 -
#16 Extended offline Completed without error 00% 8703 -
1 of 1 failed self-tests are outdated by newer successful extended offline self-test # 3
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
T’as tourné 220 heures sans faire évoluer les trucs chiant (Reallocated_Event_Count , Offline_Uncorrectable ), donc bon, le disque est a risque mais fonctionne encore.