ouep, mais là par exemple, j’avais une question sur Excel et faute de trouver une réponse via une recherche Google, et avant de polluer la section « Dev » du forum, j’ai tenté ma chance avec Copilot :
« une formule excel peut-elle utiliser une référence de cellule générée au moyen d’une autre formule? »
Il me répond :
« Oui, une formule Excel peut utiliser une référence de cellule générée au moyen d’une autre formule. Il existe plusieurs façons de le faire, mais l’une des plus courantes est d’utiliser la fonction DECALER »
Et en effet, j’ai testé, ça marche. Ca fait 2 fois aujourd’hui que cette IA répond correctement à mes questions…
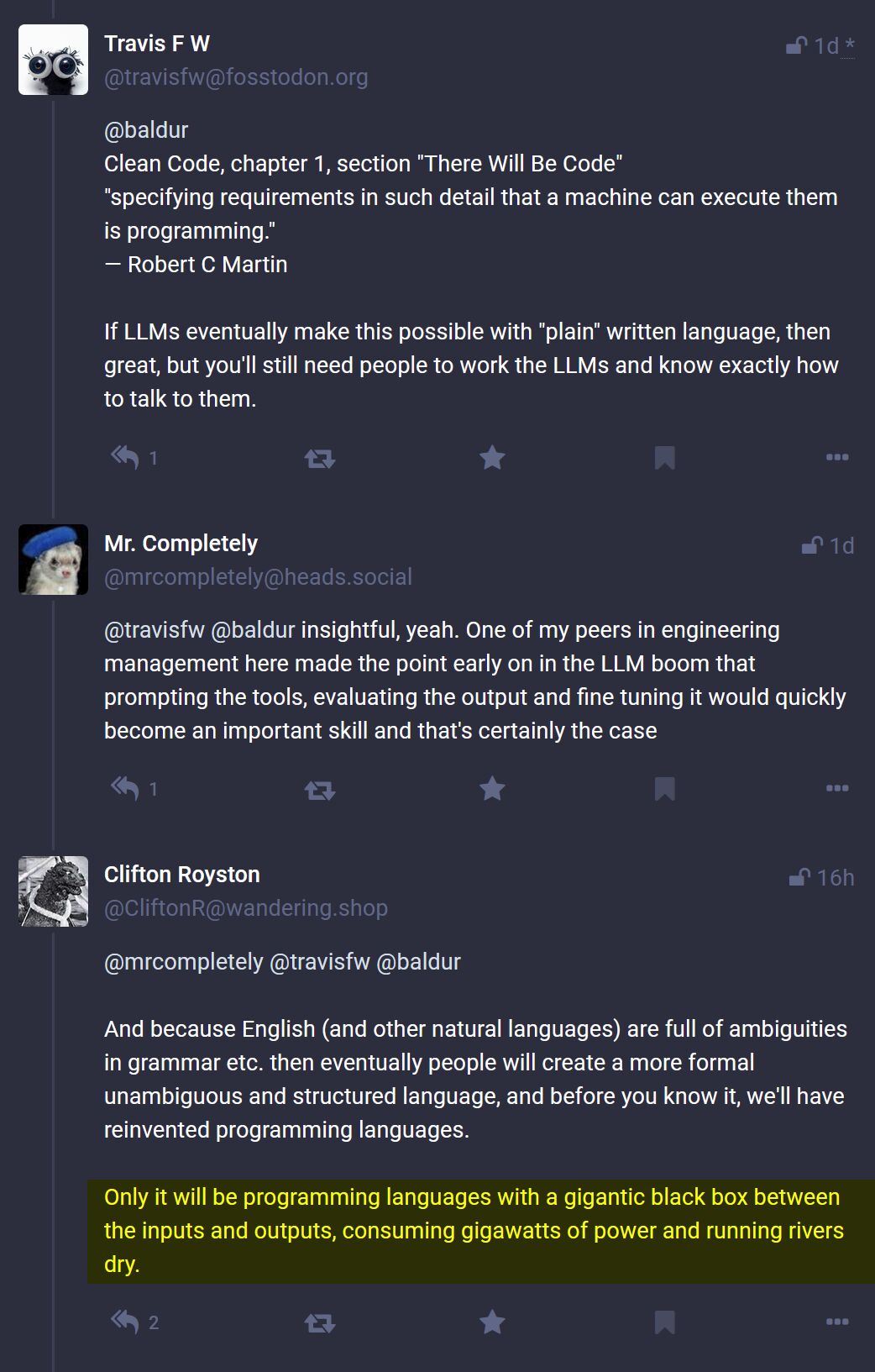
On nous a filé Github Copilot au taff, et on va pas se le cacher, le chat est puissant quand même… Ça remplace très très largement ce qu’on cherchait sur StackOverflow avant
Perso je me sers de l’auto complétion Copilote tous les jours au boulot pour du dev front-end (et parfois backend). Parfois ça fonctionne pas (rien trouvé ou pas ce que je veux) mais la plupart du temps, c’est quand même très bien. Ça me permet d’aller facilement 2x plus vite, pour $10/mois ça doit être mon meilleur abonnement vu le confort apporté et le temps économisé…
Perso je m’en sers pas pour recoder le moteur de Quake mais plutôt pour du code boilerplate, CRUD et des variations de mon propre code. Et je parle uniquement de GitHub Copilot, pas de tout ce qui est AI générative pour des aspects artistiques bien sûr.
Edit : Il y a un procès qui va bientôt arriver et qui va certainement régler la question ?
Pareil j’utilisais Copilot depuis des mois, et Copilot Chat depuis la beta, ça marche bien, mais je teste de nouvelles choses :
Le mec est un des fondateurs d’ollama, et explore quelques pistes open source pour remplacer Copilot. Il a quelques vidéos sur le sujet qui se suivent plus ou moins dans sa timeline, je ne vais pas tout linker ici déjà que c’est HS.
TLDR: l’extension Continue pour VS Code remplace à merveille Copilot Chat pour peu qu’on lui file un LLM efficace (là y a Codellama 70b en free trial ça déboîte mais je ne connais pas les limites du free trial), par contre pour les suggestions automatiques j’ai essayé l’extension Llama Coder, il fait la démo avec un modèle très léger (deepseek-coder:1.3b-base-q4_0), mais pour ma part, ça n’a pas été convaincant sur du Dart, ça réagit vite, mais à côté, peut être une question de context trop limité, et j’ai essayé avec des modèles un peu plus costaud mais c’est tout de suite trop lent sur mon MBP M1 Pro 32GB
Oui c’est au procès que je faisais référence mais bon, comme il ne faut pas empêcher les grosses boîtes de s’approprier toute la création d’internet, j’ai peu d’espoir.
C’est vrai que même si l’issue du procès est positive pour MS, ça ne voudrait pas dire grand chose sur le fond du sujet… Si les auteurs de code volé peuvent être identifiés, se faire indemniser et leur code retiré du dataset, ça serait l’idéal.
@romlefou merci pour les liens, je savais même pas que ça existait… Je passerai avec plaisir sur une alternative open source à Copilot
Le principe même des ia génératives c’est de « blanchir » la donnée, en tout cas c’est ce qu’annoncent les boîtes qui font de l’IA (forcément).
D’un autre côté elles refusent de donner des explications sur les datasets utilisés par ces mêmes IA au nom du secret industriel.
Encore un cas aberrant d’ultra libéralisme dévoyé, exactement dans la même foulée que les crypto-monnaies, les NFT etc…
Leur point commun est d’abuser de marchés non-regulés, de s’abriter derrière de la techo-croyance et dans 99% des cas d’apporter des solutions avec un rapport utilité/ressources consommées abyssal à des problèmes que l’on n’a pas…
Bref je m’étais lancé dans un pavé contre l’utilisation irresponsable qui est faite de ces outils au regard des ressources consommées mais c’est vain.
Alors c’est pas compliqué du tout, tout ce que dit cet article c’est que les poursuites liées à l’utilisation de copilot seront directement supportées par Microsoft.
Ça n’a absolument rien à voir avec le problème sur les données utilisées pour entraîner les IA, c’est juste un moyen pour Microsoft de se faire de la pub en rassurant ses clients.
Le procès qui se prépare ne réglera probablement pas le problème définitivement mais pourrait servir de base à la législation spécifique autour des LLM.
Non, l’article parle du code sous copyright et de ce qu’ils font pour éviter d’en prendre dans leur set de données
We have built important guardrails into our Copilots to help respect authors’ copyrights. We have incorporated filters and other technologies that are designed to reduce the likelihood that Copilots return infringing content. These build on and complement our work to protect digital safety, security, and privacy, based on a broad range of guardrails such as classifiers, metaprompts, content filtering, and operational monitoring and abuse detection, including that which potentially infringes third-party content. Our new Copilot Copyright Commitment requires that customers use these technologies, creating incentives for everyone to better respect copyright concerns.
Je trouve excellente cette expression. Ça résume bien l’inquiétude quant à l’utilisation des données en IA.
C’est bien gentil les filtres, mais ce sont les références des sources de données qui sont importantes. Comme dans n’importe quel source d’informations, articles de journaux, Wikipedia, et surtout articles scientifiques on est censé voir les sources initiales.
Du peu que j’ai compris de l’IA générative c’est que ça utilise les connaissances pour créer des liens entre celles-ci transformées en données : j’ai bien peur qu’au cours de cette transformation on perde la source de la donnée initiale : est-ce qu’on pourra voir la liste des sources initiales après la réponse du chatbot ?
J’ai l’impression, à tord peut-être, que le filtre est en aval, du côté de la réponse, mais pas ou peu en amont, du côté de la récolte d’informations. En plus la liste des sources initiale a 2 intérêts: la référence de la source effective, et la licence effective concernant les droits d’auteur.
Mais bon comme c’est une boîte noire avec potentiellement des quantités colossales de données en amont, je rêve complètement je pense pour avoir la liste des sources et pouvoir juger sur pièce, voire pouvoir acquérir une licence si nécessaire d’une information sous copyright.
Édit : et voir l’inspiration pour les illustrations ! Je rêve complètement, ça prouverait au contraire l’origine de la source, alors que « non, on est blanc comme neige ».
« crée des liens »: de ce que je comprends, peu ou prou (cf l’article en dessous)
« est ce qu’on pourra voir la liste des sources initiales »: je ne sais pas comment.
C’est tout le coeur d’un des procès contre je ne sais plus lequel de Dall-E, Midjourney ou StableDiffusion, qui démontrait que les modèles de diffusion sont en fait des modèles de compression lossy, et donc stockent littéralement la source de l’entrainement.
Ce qui donne des paradoxes assez rigolo à défendre, ce que tu pointes de façon assez claire avec ta phrase.
A mon avis on va arriver à un point bascule copyright vs faire de la thune avec l’IA.
Évidemment tout ce qui est Open Source mais dont le code n’est pas censé être réutilisé dans des produits commerciaux va se faire blanchir sans entrave… Je vois mal L’Electronic Frontier Foundation, par exemple, peser dans la balance quand des états entiers (la France en premier lieu en Europe) sont prêts à tout pour être le prochain eldorado de l’IA.
Le problème du copyright dans les logiciels n’est pas nouveau et il sera quasiment impossible de prouver que l’on est à l’origine d’un algorithme (c’est déjà pas évident). Tout ce que l’on va faire c’est tuer le logiciel libre et revenir au niveau des années 80.
Le risque c’est, qu’une fois qu’il n’y aura plus de code non-copyrighté, le système s’écroule de lui même.
Et puis c’est super les codes générés mais pour debugger du code, il faut le comprendre et l’industrie du logiciel marche quand même vachement sur la maintenance des systèmes…
et encore on a meme pas encore parlé des coûts environnementaux ou humains, de la confiance qu’on peut porter à ce qui sort d’un modèle probabilistique, ou du fait que si c’est l’ordinateur qui fait tes devoirs, c’est pas dit qu’on retienne beaucoup de choses
L’article, dont tu as posté le lien, « Large language models, explained with a minimum of math and jargon » de Timothy B. Lee, est didactique, bien écrit et clair. Merci.
Je n’ai pas accès à l’article mais démarrer d’entrée en donnant accès à nos données personnelles à des entreprises étrangères sous prétexte qu’il faut absolument faire du fric ça me donne envie de hurler !
Et dire que ce ne sera pas des entreprises étrangères c’est la même chose que d’affirmer qu’on a un vrai cloud européen