Dernièrement j’ai essayé de faire des rapprochements entre des libellés d’analyses de pH et d’autres analyses de labo.
Pour cela arbitrairement par expressions régulières je retrouvais des codes identifiants qui me servait à faire des jointures en R. Puis après je découpe le reste en mots. Et je compare avec une autre liste en donnant un score pour ceux ayant le plus de mots identiques. Mais c’est assez lourd pour la partie sans identifiants d’où des pré-calculs toutes les demi-journées. J’utilise tidyverse et plus particulièrement dplyr en R. J’ai vu le package R fuzzy join mais même si ça apporte de la souplesse ça fait appel semble-t-il aux mêmes technologies sous jacentes, je n’ai donc pas poussé plus loin sur fuzzy join.
J’ai aussi essayé de rapprocher des dénominations de plantes à des dénominations de taxons, ceci avec des Like en SQL mais sans la définition latine. Le problème c’est que ça peut partir vite en vrille car les adjectifs et prépositions, sans parler des sous-espèces peuvent faire plein de jointures inappropriées, donc je me contente de chercher la dénomination officielle vernaculaires, en entier, dans mes listes de commentaires.
J’ai essayé de chercher sur internet , mais je manque de vocabulaire dans le domaine, des solutions en R ou python qui sachent rechercher dans un dictionnaire de mots en donnant davantage de poids à ces mots. Il faudrait aussi ne pas perdre de vue qu’il faudrait que ça soit un minimum compilé, sinon ça ne sera pas plus puissant que mes réinventages de roue.
Le top serait qu’il apprenne des données (mais dans un premier temps ça risque de complexifier pour rien ma demande).
Mais je crains que mes demandes fassent appel à des usines à gaz ou alors à des concepts d’IA que je commence à peine à comprendre.
Facile, mais je ne parlerai qu’après bouffé tout ton CIR.
Plus sérieusement, si j’ai bien compris, c’est de la comparaison sémantique entre deux textes.
Ce que tu fais pour l’instant c’est du text mining sans prendre en compte le sens des phrases. C’est une approche qui est pas mal du tout et qui peut être très rapide avec les bon outils ( comme KH Coder pour n’en citer qu’un). Pour un premier tri c’est intéressant. Il faut quand même, dans un premier temps, supprimer tous les « stop word » pour alléger le document. (Ex de liste Fr: https://www.ranks.nl/stopwords/french)
Pour prendre en compte la sémantique, il faut ajouter un traitement « de compréhension » en plus.
On pourrait presque résumer leurs fonctionnement avec:
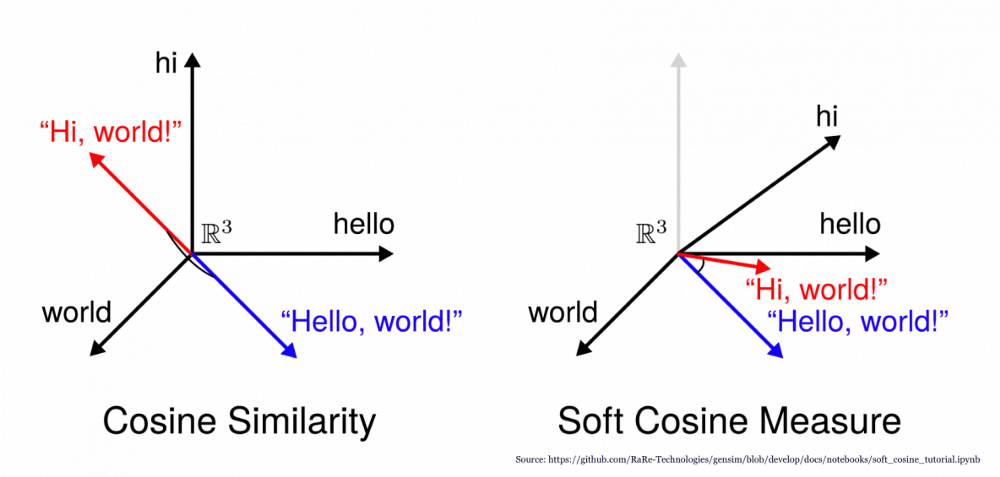
Tu projettes dans un espace vectoriel tes textes et ensuite tu calcules la distance entre.
Toutes la difficulté est de trouver l’espace, la fonction de projection et le calcul de distance . Voilà à quoi ça pourrait ressembler :
(Image trouvé au pif) en 3D
Ben dis donc. Excellent ! Qu’est ce qu’on ferait sans tout ces chercheurs Je n’ai jamais été à l’aise avec les théories et recherches pendant mes études, mais maintenant que j’ai des applications réelles je comprend à rebours ces cheminements.
Ha ok. Donc là c’est une solution « simple » sans IA. Et en cherchant KH Coder je trouve aussi une librairie R qui semble avoir des fonctionnalités similaires : qdap.
En tout cas le schéma est très parlant.
Je me demande si ce n’est en fait pas plus compliqué que les recherches de courbes de référence dans des courbes.
En tout cas avec ou sans apprentissage, et même sans analyse sémantique par la machine, je vois qu’un simple dictionnaire ne peut pas suffire et qu’il faut au moins obtenir l’« espace vectoriel [des] textes et ensuite calcule[r] la distance entre ».
Bon je vais déjà télécharger KH coder dès que je pourrai.