Non, installe Trae, c’est gratos ( enfin , il siphonne tout).
C’est drôle, dans quasi tous les commentaires de ce thread on pourrait remplacer AI par développeurs offshore ![]() C’est aussi une idée magique de nos amis les managers pour gagner de l’argent.
C’est aussi une idée magique de nos amis les managers pour gagner de l’argent.
8 « J'aime »
Un fil à la patte en fait…
… qui potentiellement nous siphonne en plus !
Je comparerais ça à une pelleteuse Vs une pelle. Avec la pelleteuse, il y a plein de travaux que tu peux faire rapidement. Mais, si t’as des lignes électriques enterrées, tu vas tout atomiser si tu fais pas gaffe. Est-ce que pour autant, le fait que la pelleteuse te coûte X milliers d’euros par jour de location et le risque de mal l’utiliser la rend inutile ? Est-ce que dépendre d’un prestataire de location pour creuser une tranchée est une mauvaise idée ? Non, c’est juste que comme tout outil, la formation et l’expérience vont t’apprendre à y faire appel ou à t’en passer suivant tes cas d’utilisation.
3 « J'aime »
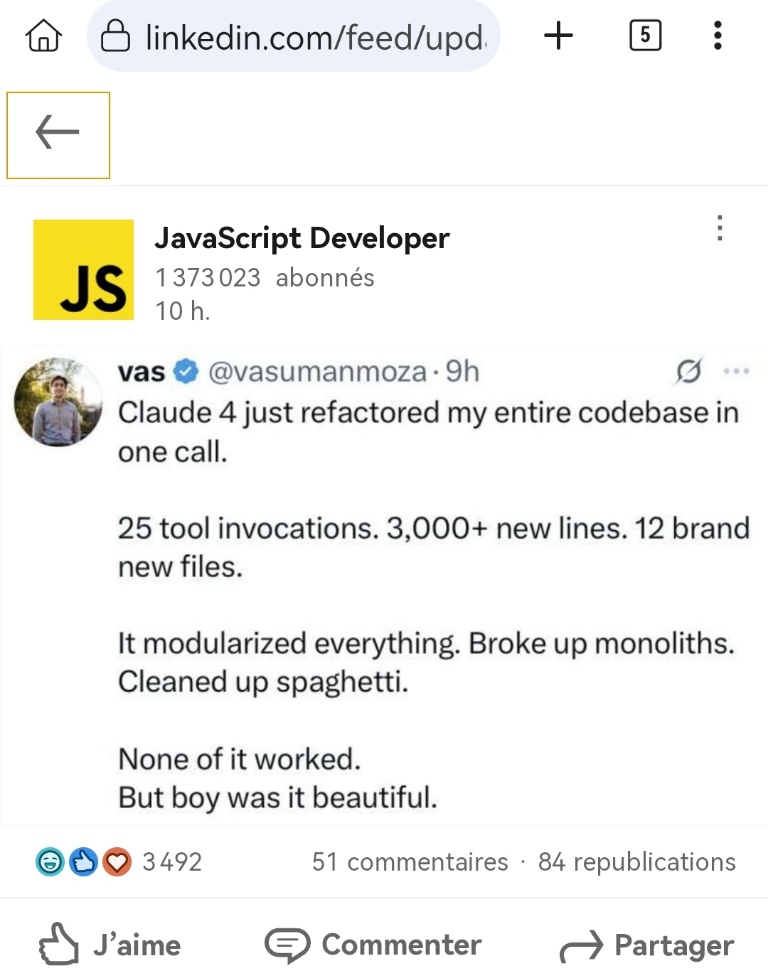
J’ai vécu ça en vrai, plein de fois. Tu demandes une petite modif, c’est beau, toute ton appli explose en flammes. Le code généré semble crédible. Quand l’échelle des modifs est trop grande, l’efficacité des outils s’effondre, même sans atteindre la taille max du contexte.
En fait, dans un LLM, il n’y a pas de notion absolue de priorité des instructions. Un user prompt est une instruction, un bout de code existant est une instruction, un system prompt est une instruction. Chacun de ces éléments va pousser le modèle à générer du code, c’est à dire à chercher le texte le plus probable par rapport à la demande. Quand la masse de code et d’informations atteint un certain seuil, la priorité des prompts sur le reste se dilue et le LLM commence à faire n’imp. C’est même pas une histoire de taille de contexte, d’ailleurs. C’est à mon sens un problème insoluble, comme les hallucinations, on peut juste espérer qu’on saura le minimiser. En attendant, ça demande un suivi rigoureux de la taille du contexte et des opérations qu’effectuent les outils sur le code.
Vous laisseriez pas un junior pousser du code en production sans supervision, vous ne devez pas le faire avec un LLM.
2 « J'aime »
Certes, mais au moins un junior on peut espérer qu’un jour il progressera suffisamment pour être autonome.
Comme un gamin qui finit par ne plus avoir besoin de couches, alors qu’un chien il faudra toujours ramasser son caca.
1 « J'aime »
Ton junior coûte probablement plus cher que les max 20€ de l’heure d’un Claude Sonnet 3.7 et il sera encore plus cher quand il saura pousser du code de manière autonome en production.
Oui, ça ne fait pas plaisir à entendre, mais c’est le raisonnement derrière tout ça.
Pour les projets perso, un junior virtuel en comparaison de pas avoir cette aide, c’est la différence entre sortir le projet et ne pas avoir le temps de le faire.
1 « J'aime »
J’ai retrouvé des emoji typique d’un code généré par GPT4 dans certains de mes packages… je suis un peu dépité par mes « juniors ». Ca montre qu’ils n’ont meme pas relu ce qu’ils ont poussé.
Il faut changer de chat:

(ok elle est un peu tordue celle-là)
1 « J'aime »
C’est aussi une commune dans le Gard
1 « J'aime »
")
Je me sers de plus en plus des AI pour avoir une sorte de documentation en temps réel. En ce moment je me remets à Adobe Premiere. J’étais en train de découper des bouts de vidéos et je les déplaçais à la souris de manière assez fastidieuse. Je lui demande comment je pourrais faire ça plus simplement et il me répond directement Q (trim before cursor) et W (trim after cursor). Je n’y aurais pas pensé tout de suite, surtout que je ne savais même pas quoi taper dans Google ou dans la doc pour trouver ça. Un peu comme un LMGTFY++ ![]()
1 « J'aime »
De l’importance de ne pas laisser les IA tout faire, sans double vérification …
2 « J'aime »
Ou ne pas laisser n’importe qui (voir l’IA ?) Valider les pull requests :
2 « J'aime »
Thomas Dohmke, CEO de GitHub, quitte l’entreprise. La plateforme de développement, propriété de Microsoft depuis plusieurs années déjà, mais restée relativement indépendante, sera désormais intégrée à l’organisation CoreAI de Microsoft.
(..)
Pour GitHub, le nouvel organigramme pourrait signifier une concentration accrue sur l’IA. Microsoft mise massivement sur ses assistants d’IA depuis plusieurs années, et GitHub Copilot n’y fait pas exception
https://datanews.levif.be/actualite/business-it/developpement/github-voit-son-ceo-sen-aller/
1 « J'aime »
Mais, ça fait plusieurs années que Github copilot pompe allègrement les repos.
Qu’est-ce que ça va changer concrètement ?
1 « J'aime »
Pour l’instant c’est un changement d’organisation interne à Microsoft. Tout le reste ce sont hypothèses fumeuses pour produire de la ligne et capter du temps de cerveau.
Ça ne sert pas à grand chose de se faire des films.
3 « J'aime »
Ça commence à devenir le bordel dans Copilot, je ne sais plus à quelle AI me vouer. Si ça continue il faudra une AI pour interroger plusieurs AI. D’un autre côté c’est bien, on a rarement eu autant de concurrence dans un domaine.
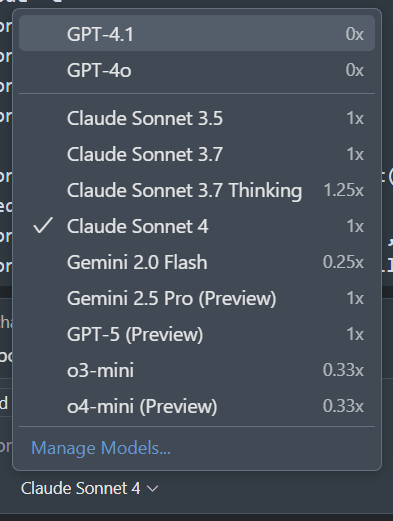
Je crois que c’est ce que fait OpenAI, en dehors des APIs, c’est maintenant impossible de choisir un modèle