La grosse nouveauté c’est le lecteur d’epub. Il permet de lire ses bouquins sans avoir à les télécharger.
C’est moins utile que pour les BD puisque les epub sont beaucoup plus légers que les BD, mais c’était réclamé par pas mal de monde.
Tout d’abord merci pour le logiciel, il vas me permettre de partager avec quelques personnes ma bibliothèque d’epub et de Bd’s.
j’ai installé Ubooquity sur mon serveur dédié Kimsufi, pas évident pour un néophyte comme moi, du coup je me retrouve avec quelques soucis que je n’arrive pas à résoudre, si quelqu’un peut m’aider…
Une partie de mes Bd’s ne sont pas détecté par le scan, je suppose que c’est en cause des accents, mais je n’en suis pas sur. exemple : Tome 02 - L’île des mers gelées.pdf
De plus, j’ai des scans en Jpg, il y à t’il un moyens de les lire sur Ubooquity, car je me retrouve avec des dossiers vides.
Merci
ps : Pour ceux intéresser par l’installation sur un serveur kimsufi debian wheezie, j’ai utilisé ce tuto :
Les problèmes liés aux accents proviennent souvent d’une mauvaise configuration de la locale.
Ça peut se corriger (je ne sais pas si ça marche dans tous les cas) avec l’option décrite dans ce message.
Sinon regarde ce thread sur le même sujet, il explore le problème plus en détail.
Pour le jpeg dans des répertoires, ce n’est pas possible: Ubooquity ne reconnait que les fichier de BD ou livre complet (cbz, cbr, pdf, epub…).
Pour les jpeg j’avais eu le cas, pas d’autre solution que compresser les dossiers contenant les jpeg vers du cbz ou cbr, c’etait la solution la plus simple que j’ai trouvé.
Merci à toi c’est ce que j’ai fait, je trouve dommage que les images ne soit pas reconnue quitte à pouvoir simplement les téléchargé.
Pour ceux que ça intéressent, en ligne de commande j’ai utilisé « rar a » puis « mv » ce qui donne par exemple, en se mettant dans un dossier ou vous avez une 20 de fichiers .jpg qui composent la BD.
rar a NomdelaBD.rar *.jpg
Puis
mv NomdelaBD.rar NomdelaBD.cbr
Il y à sans doute plus simple mais çà à bien marché pour moi, je me permet de mettre la solution que j’ai trouvé au cas ou cela serve.
Parce que le zip est un format supporté de manière beaucoup plus large que le rar.
Pour le rar côté dev, en fonction du langage tu peux te retrouver à devoir utiliser une lib plus maintenue depuis des années parce que c’est la seule disponible, avec les problèmes de bugs non fixés et de compatibilité avec les dernières version de rar que cela entraine.
Le zip est géré en standard dans la plupart de plateformes, avec des tonnes d’implems alternatives en cas de besoins spécifiques.
Et enfin parce que pour des BD, le rar n’apporte aucun avantage significatif par rapport au zip.
Au contraire, si la personne qui a créé le fichier rar a eu la mauvaise idée de faire une compression compacte (“solid archive”), tu le payes cash en perf CPU et conso mémoire au moment de lire la BD (pour du “random access” de page, ce que font tous les readers).
Merci pour ton message Twin. J’ai utilisé rar car j’avais lu sur un site qu’il fallait changer seulement le nom de l’extension d’un rar en cbr, ça m’as parue le plus simple. Comme fais tu pour générer des cbr avec des jpg ?
J’en profite pour te poser une autre question, est-il dangereux de ne pas activer de compte d’utilisateur pour la sécurité du serveur ? Car je trouve que c’est plus simple de ne pas donner de code et de compte à mes à amis.
Voilà, pour faire un CBR, tu “rarre” et tu renommes, pour faire un CBZ, tu zippes et tu renommes.
Les deux formats sont supportés par tous les lecteurs, mais mes arguments restent valables.
Par exemple le lecteur que j’utilise sur iOS (Chunky Reader) décompresse et repacke les fichiers RAR “solides” à l’import, pour éviter des problèmes de latence à la lecture.
Autant éviter ce genre de truc et utiliser ZIP.
Dernier conseil: quand tu compresses une BD (quel que soit le format), choisis le taux de compression le plus bas (et même pas de compression du tout si c’est disponible). La compression de fichiers JPG ou PNG ne te feras de toutes façons rien gagner en terme de taille et rendra la BD plus longue à ouvrir.
Pour la question de la protection par mot de passe: si tu n’en mets pas, ça veut simplement dire que n’importe qui qui découvre ton IP pourra se servir dans ta collection (et si Google arrive à indexer ta page ça risque de faire du monde). Donc oui c’est mieux d’en mettre un (quitte à mettre le même pour tout le monde).
Passage à Java 8 (parce que bon, hein) , amélioration flagrante du rendu des PDF (avec un impact perf, on n’a rien sans rien) et support des liens symboliques (parce qu’apparemment les gens en utilisent sans même le savoir).
Il aurait pu sauver la mise suite au changement de charte de Dropbox (en gros je ne peux plus exécuter de HTML sur Dropbox du coup je ne peux plus partager ma bibliothèque).
Malheureusement pour madame il manque certaine fonction qu’elle avait avant :
Oui Ubooquity est capable de générer un flux OPDS à partir des dossiers partagés.
Il faut pour cela activer la fonctionnalité “OPDS” dans les options avancées, sauver les settings, puis aller sur l’URL: :2202/opds-comics (ou opds-books si c’est pour les livres).
EDIT : effectivement ça fonctionne c’est moi qui n’avait pas tout inclus pour les couvertures super merci beaucoup je vais pouvoir réparer tout ça.
C’est exactement ce qu’il me fallait chapeau.
Ça fonctionne quand je mets directement mon dossier dans le secteur "Raw"
Je vais ensuite dans mon lien extérieur et je peux activer mon HTML et le consulter merci beaucoup.
Bonjour,
Merci pour ce soft bien utile que j’ai découvert il y a quelques jours et définitivement adopté. J’ai eu un peu de mal, comme beaucoup de personnes ici ^^, pour le faire tourner sur mon NAS Synology mais avec de la patience, on y arrive.
Etant totalement inculte en Linux, ça m’a contraint à m’initier à quelques bases qui me seront toujours bien utiles et je remercie tous les contributeurs de la présente page, à commencer bien sûr par le créateur du programme
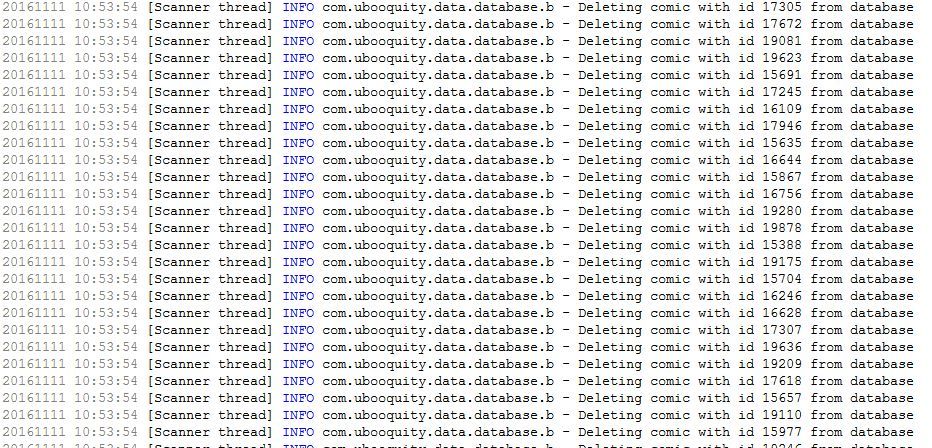
J’aurais une question sur le fonctionnement du scan qui m’échappe un peu : lorsqu’on modifie sa collection de BD (ajout ou déplacement de fichiers, renommage de dossiers…) faut-il supprimer la base de comics déjà existante dans Ubooquity avant de lancer un nouveau scan ?
Cela fait plusieurs fois que je constate que le scan normal ne tient pas compte des modifications récentes : il conserve les anciennes adresses des fichiers qui ont été déplacés depuis le scan précédent et, curieusement, il supprime de la base un très grand nombre de titres (même si je n’ai effectué que quelques déplacements ou renommage de fichiers)
Au final, je me retrouve avec 1/4 des titres manquants dans Ubooquity (aujourd’hui, après un gros ajout de fichiers, j’arrive même un nombre total de BD dans Ubooquity inférieur à celui que j’avais avant cet ajout )
Avant de supprimer la base et relancer un scan (qui prend dans mon cas plusieurs heures:blush:, d’où ma réticence) j’aurais aimé savoir si quelqu’un avait déjà constaté cette anomalie et eventuellement ce qui peut en être la cause?
Cela peut-il provenir de mon système de classement ? Mes ebooks sont dans des dossiers au nom de leurs auteurs,à la racine de ces dossiers pour les one-shot ou dans des sous-dossiers pour les séries.
lorsque Ubooquity fait un scan, il passe récursivement sur tous les fichiers contenus dans les répertoires partagés.
Il ajoute dans sa base de données les fichiers qui n’y étaient pas déjà et supprime ceux qui n’existent plus.
Aucun opération manuelle à faire donc (pas la peine de supprimer la base).
Ce qu’il faut savoir, c’est que pour Ubooquity, un fichier est identifé par son path (le “chemin” + le nom du fichier). Si tu déplaces un fichier dans un autre répertoire, Ubooquity fera donc une supression et un ajout en base. Il n’a pas de moyen de savoir que le fichier déplacé était déjà présent en base.
Suivant le même principe, si tu renommes un répertoire, tous ses fichiers seront supprimés de la base puis réajoutés (en fait dans les logs tu verras d’abord la suppression puis l’ajout).
Autre point: le scan n’est pas immédiat, il se déclenche régulièrement selon tes préférences et peut aussi être lancé manuellement via l’interface d’admin.
Dernière chose qui peut expliquer certains problèmes: Ubooquity a du mal avec les liens symboliques.
Donc il vaut mieux, dans la mesure du possible, indiquer les path réels dans les paramètres de fichiers partagés plutôt que des liens symboliques. (il me semble avoir lu que sur les NAS Synology certains répertoires étaient présentés via des liens symboliques créés par le système, donc on peut en avoir sans les avoir créé soi-même).
Voilà, j’espère que ces quelques explications pourront t’aider, n’hésite pas si tu as d’autres questions.
Tout d’abord l’environnement : NAS Synology DS416play (x86 donc) avec 1Go de ram.
J’ai un peu lutté pour l’installation, notamment le chemin de Java qui manifestement n’est pas le même en fonction de la version de DSM.
Le serveur se lance correctement et commence à récupérer les BD du répertoire. Mais c’est suuuuuuper lent ! Bien que la conso CPU ne dépasse pas 20% tout le NAS est ralenti et chose curieuse, les téléchargements en cours tombent pratiquement à zero.
L’accès au serveur via browser est lui aussi extrêmement lent (en local).
Lorsque je coupe le serveur ubooquity, tout revient à la normale.
Dommage, l’idée me plait vraiment beaucoup, mais je ne sais pour quelle raison, c’est inutilisable chez moi, en tout cas sur mon NAS.
Edit : Autre comportement étrange lorsque le serveur ubooquity est actif, j’ai une foultitudes de connections admin sur DSM. Genre plusieurs dizaines à la minute.


 )
)