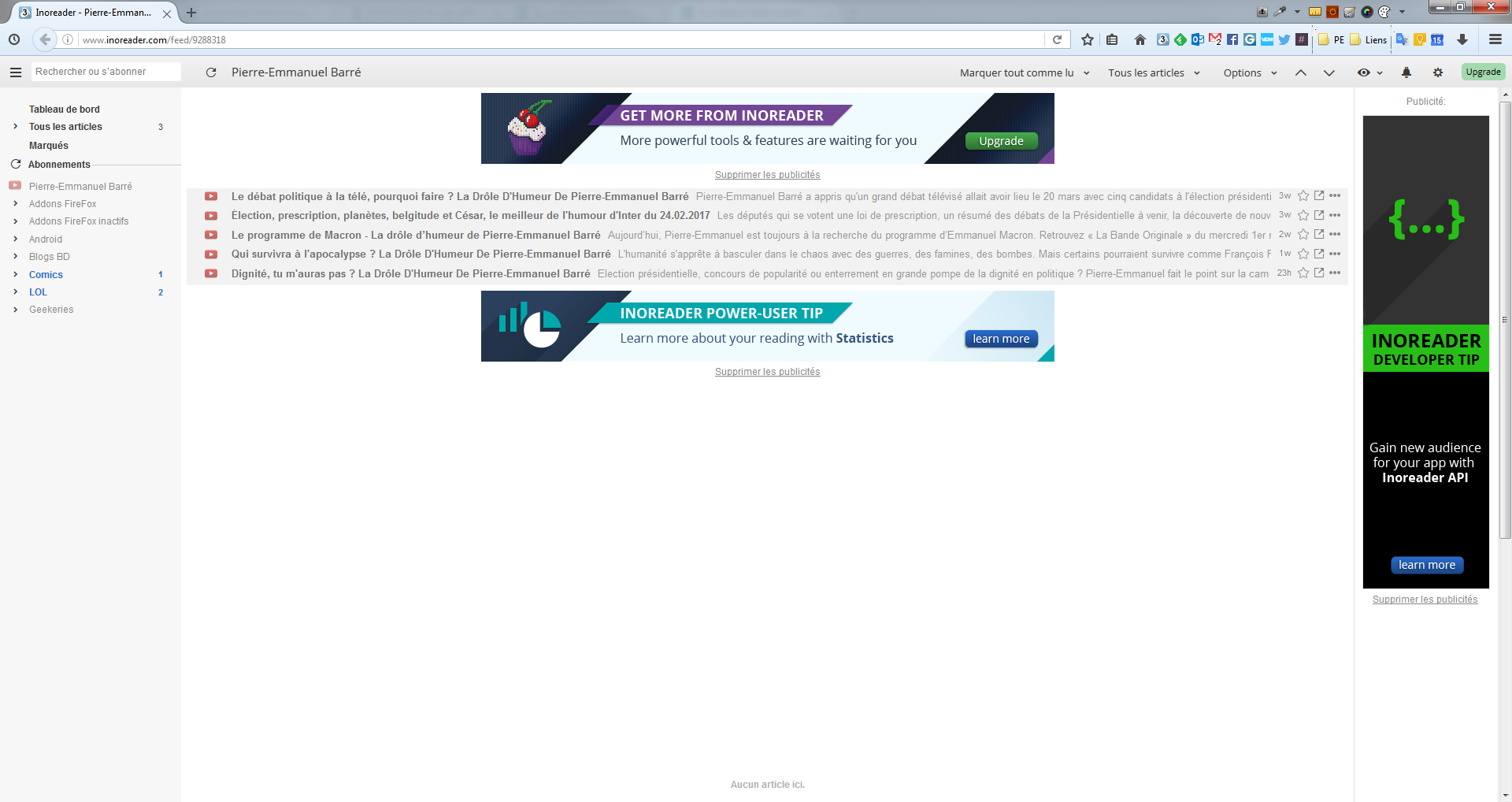
Oui, et je confirme que je n’ai que 5 vidéos dans la liste :
Et de la pub aussi depuis ce matin… 
Pareil pour la pub, apparue ce matin aussi. Par contre pour le flux je ne comprends pas.
Ahhhhh parfait ça ! Vu que certains sites ont décidé de ne fournir de RSS, ça va simplifier le suivi.
Yep, c’est le grand soucis des RSS quand tu as un grand nombre de sources.
C’est exhaustif mais ca n’est pas précis/pertinent.
T’as plusieurs facons de traiter ce problème imho. Tu peux te faire un dossier ou tag ou autre pour les flux que tu considères comme immanquable. Ceux la tu sais que tu veux pas en louper un seul article.
Ceux qui sont verbeux ou pour lequel tu portes moins d’intérêt, tu peux les mettre dans un autre coin. C’est bien d’avoir l’exhaustivité par contre puisque tu vas pouvoir effectuer des recherches/filtres sur l’ensemble des articles qui vont constituer ta base de connaissance.
Après pour le tri par pertinence, le problème est finalement assez complexe… J’ai vu sur Discord quelqu’un parler de regroupement d’articles sur le même sujet. aka clusterisation. C’est une techno assez couteuse et chiante à maintenir (je parle d’expérience, je m’occupais du product chez Wikio à l’époque) et je doute qu’un simple lecteur RSS se lance sérieusement dans ce genre de galère.
Idem pour la pondération des articles. C’est complexe, et ca peut souvent etre sujet à discussion sur ce qu’on considère comme pertinent ou pas comme variable…
Ce qu’on faisait par exemple chez Wikio, c’était un mélange de pondération par source (“ars technica” a plus de valeur que “le monde” sur le domaine de “la high-tech”, par exemple), puis de pondération par indices sociaux (nombre de retweets des articles, nombre de likes sur FB, nombre de backlinks vers l’article etc…) Et enfin la pertinence vis a vis du sujet que tu cherchais, ce qui n’est pas trop une approche RSS fondamentalement…
Bref, c’est très chiant à mettre en place de facon magique. Et si tu fais confiance à des algos de selection et de ranking d’articles, ou autrement nommé curation automatique, tu vas vite tomber dans les même biais que si tu lis tes news à travers Facebook.
Je rêve d’un produit qui permette de le faire de facon intelligente et surtout ouverte.
Un début de piste avait été évoqué il y a une dizaine d’années avec l’APML : https://en.wikipedia.org/wiki/Attention_Profiling_Mark-up_Language
En gros c’est un fichier qui stockerait tes centres d’attention, avec une séparation entre tes contextes d’utilisation (“a la maison”, “au travail”…), ainsi que entre ce qui est implicite (“t’as cliqué plein de fois sur Emma Watson, donc ce sujet t’intéresse”), et ce qui est explicite (“je VEUX voir plus d’infos sur le raspberry. même si je clique pas dessus”).
Dedans tu stockes des concepts (“raspberry”, “emma watson”), et tes sources (“le monde”, “ars technica”), avec une pondération associée.
A l’aide de ce fichier, les clients RSS (par exemple) devraient pouvoir te trier automatiquement tes articles et te faire ressortir les articles que tu devrais considérer comme étant le plus pertinent. T’ajoute une petite couche de social dessus éventuellement, pour faire remonter ce qui buzz et pas t’enfermer dans une autre bulle, et tu aurais une solution qui serait a mon gout bien meilleure que celles qui existent.
L’APML ca a été adopté par une poignée d’acteurs, comme Blogline, et c’est tombé dans l’oubli.
Il y avait du beau monde pourtant dans la liste des contributeurs : https://web.archive.org/web/20131014095735/http://apml.areyoupayingattention.com/geeks/workgroup/
Et puis la dataportability, sur des notions comme l’attention, au final je crois que c’est tellement sensible que personne ne voudrait vraiment s’ouvrir pour que l’on puisse partager ca entre les services…
Malheureusement, je crois que tout le monde s’en fout de ces histoires de curation…
Parceque Inoreader passe en lu automatiquement les articles qui ont plus de 4 semaines. Si tu lui demandes d’afficher « all » et pas juste les « unread » tu verras les autres apparaitre
Nope… toujours que les 5 derniers…
Perso j’utilise la fonction « recently read » qui affiche en haut les derniers lus, peu importe la date de publication
Tu parles bien du flux http://www.inoreader.com/feed/9288318 et pas du tien à base de morning-retreat-1911?
Je note la fonction « Recently read », ça pourra servir. 
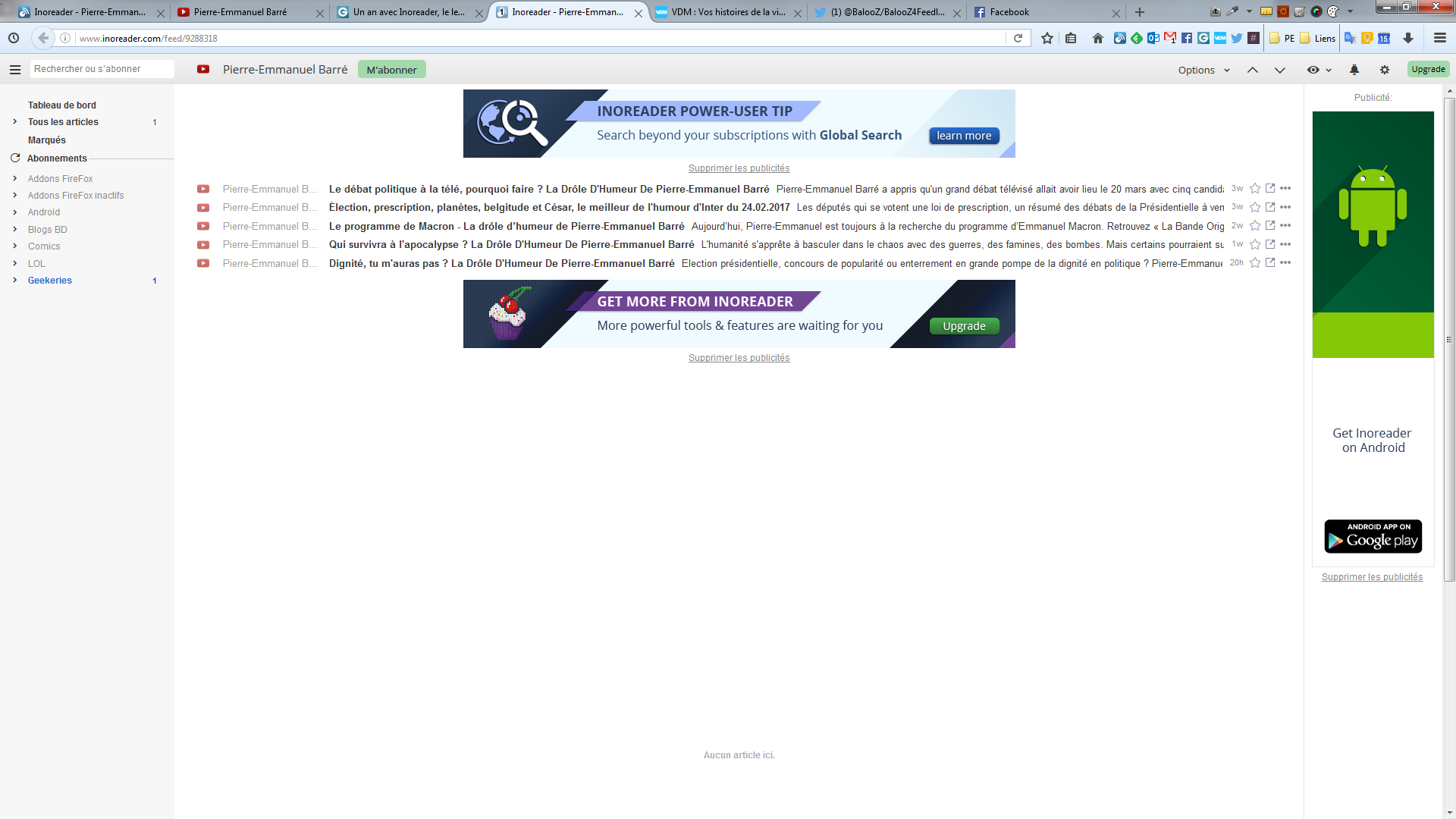
Pour le flux, tout à fait, voici ce que ça donne quand tout est lu et que je regarde le flux total :
Merci pour ce post ! J’ai l’impression d’avoir retrouvé Google Reader
En ce moment j’utilise Reeder sur Mac que je synchronise avec un compte Feedly mais je vais tester Inoreader et ses fonctions un peu plus avancées !
Ça donne quoi si tu y vas en navigation privée ?
Ah tiens, bien mieux en effet… bizarre.
Il faut noter qu’officiellement YT ne supporte plus les flux RSS hein, tout ça c’est de la bidouille. Perso j’ai tout viré de mes parsers RSS. Je check direct sur YT quand j’ai le temps et j’ai plusieurs comptes pour les différents types de flux. ![]()
Autre ruse pour les sites sans RSS : la recherche Google News ! Je viens de découvrir ça comme un noob… Il est possible de suivre un site via son feed d’info Google News. L’update est décalée mais ça fonctionne. ![]()
L’url est du genre http://news.google.com/news?hl=en&gl=us&q=NOMDUSITEdansgnews&um=1&ie=UTF-8&output=rss
EDIT : je rajoute pour le fun un feed nickel pour Dilbert.
Je me réponds à moi-même puisque je viens d’ajouter un flux et que j’ai eu ce message :
L’ordre de tri Les plus anciens d’abord n’affiche que les articles d’un mois ou moins.Cela vous permet de rattraper la lecture interrompue d’un blog sans repartir du tout début.
Pour consulter des articles plus anciens, utilisez le défilement infini de l’ordre de tri Les plus récents d’abord ou recherchez l’article si vous savez l’identifier.
Un gros merci 
Moi qui ne jurait que par Netvibes, j’ai essayé Ino et ce fut une révélation.
Bon, j’ai passé 30minutes à récupérer tous mes sites, plus 10 de plus après avoir remarqué qu’il gérait des sites que NV ne daignait même pas prendre en compte et des playlist Youtube plutôt que les chaînes entières.
Du coup, j’ai puis vidé mes favoris 
A la mort de GReader, j’ai switché sur Newsblur et finalement pris un abonnement payant pour pouvoir caser tous mes flux. Et bien merci pour cette découverte, la version gratuite fait le taf, les options payantes ne me sont pas utiles, et j’aime beaucoup l’ergonomie.
Tout pareil, du coup j’ai résilier l’abo à newsblur et fais le switch complet sur inoreader. J’ai longtemps hésiter entre lui et theoldreader, et finalement ce papier a achevé de me convaincre. Je suis moins embalé par l’appli mobile par contre, il manque des boutons previous/next par exemple, devoir swapper à gauche ou à droite en lecture détaillée m’embête beaucoup.
Vu comme l’appli Newsblur ramait sur mon téléphone, je suis pleinement satisfait pour l’instant de la nouvelle.
Ouais l’application avait de nombreux problèmes aussi, ça rame comme tu le dit et elle n’a jamais su gérer correctement les flux de plus de 80 articles.
Si dans les prochaines semaine Cafeine venait à se volatiser mystérieusement, la première cave à fouiller pour tenter de le retrouver serait celle du developpeur de newsblur. Suivie par celle de Chris Roberts.
Après quelques jours de test j’ai switché aussi. L’UI web est au top et les app iOS cartonnent. Je trouvais déjà Newsblur agréable mais là c’est vraiment au dessus.